Le RAG (Retrieval Augmented Generation) n’est pas un sujet entièrement nouveau. Chez Usabilis, nous avons choisi de ne pas nous exprimer immédiatement : nous avons préféré prendre le temps d’expérimenter, de tester ces approches sur nos propres terrains, et de construire une vision étayée plutôt que de suivre la tendance.
Le RAG est un mécanisme qui permet à un modèle de langage (LLM) de chercher dans vos propres données avant de générer une réponse.
Appliqué à la recherche UX, il ouvre une possibilité nouvelle : interroger l’ensemble de vos études passées en langage naturel et obtenir des réponses sourcées, traçables, avec les verbatims et les contextes d’origine.
Mais comme tout outil, le RAG a des limites qui demandent un cadre méthodologique clair. Cet article explique le mécanisme, montre les cas d’usage concrets en UX Research, et pose les garde-fous nécessaires.
Le RAG expliqué simplement : pourquoi c’est différent de « demander à ChatGPT »
Le problème que résout le RAG
Un LLM classique répond à partir de ses données d’entraînement générales. Il ne connaît pas vos utilisateurs, vos études, ni vos verbatims.
Posez-lui la question « Quels sont les principaux irritants de nos utilisateurs sur le parcours d’onboarding ? » Il va produire une réponse plausible, mais déconnectée de votre réalité terrain.
Le RAG résout ce problème en ajoutant une étape de recherche avant la génération : l’IA consulte d’abord vos documents, puis génère une réponse fondée sur ce qu’elle y a trouvé.
Le mécanisme en trois étapes
Étape 1, l’indexation : vos données (transcriptions, rapports, notes) sont découpées en segments et converties en représentations numériques appelées embeddings, stockées dans une base vectorielle.
Étape 2, le retrieval : quand vous posez une question, le système cherche les segments les plus proches sémantiquement de votre requête. Ce n’est pas une recherche par mot-clé : c’est une compréhension du sens.
Étape 3, la génération : les segments retrouvés sont injectés dans le prompt du LLM, qui génère une réponse en s’appuyant sur ces extraits spécifiques, avec la possibilité de citer ses sources.
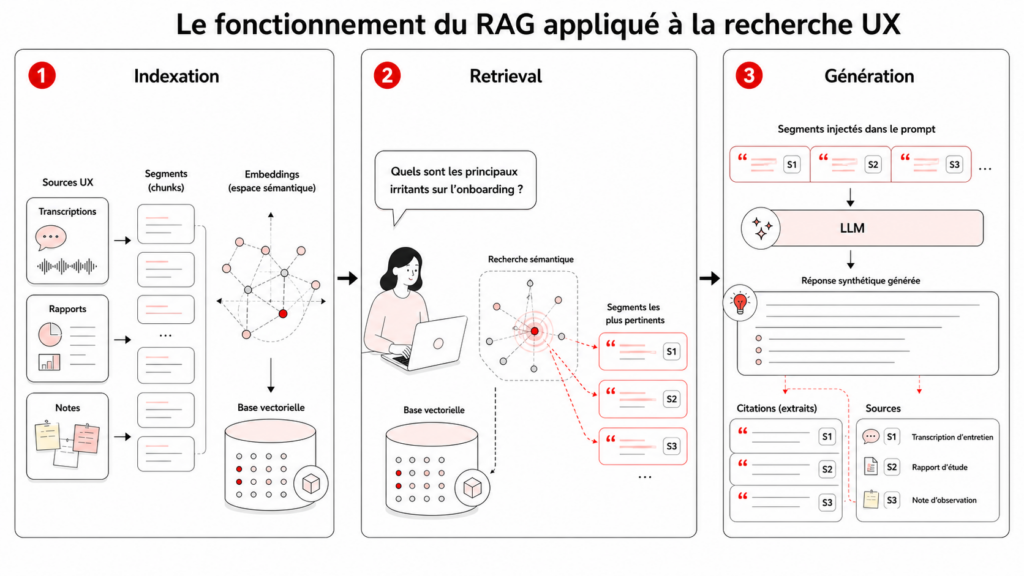
L’analogie la plus parlante : le RAG fonctionne comme un examen à livre ouvert. Le modèle a accès à vos documents pendant qu’il répond, au lieu de répondre de mémoire.
Ce que ça change concrètement pour le chercheur UX
Le bénéfice principal est ciblé : permettre au chercheur UX de passer moins de temps à restituer les faits collectés, pour se concentrer sur ce qui a de la valeur, c’est-à-dire la production d’insights, le desk research et la mise en oeuvre des recommandations.
Concrètement, cela signifie passer de la recherche par tags et mots-clés à la recherche par intention, et obtenir des synthèses sourcées plutôt que de relire 40 transcriptions avant de pouvoir commencer à analyser.
Cas d’usage concrets du RAG en UX Research
Interroger un référentiel de recherche en langage naturel
Le cas d’usage le plus direct : connecter un système RAG à un repository centralisé (Dovetail, Condens, Notion, Confluence) pour interroger les études passées en langage naturel.
Exemple : un chercheur UX prépare une nouvelle étude sur la facturation et demande « Qu’ont dit les utilisateurs PME sur la facturation automatique lors des études du Q3 ? » Il obtient une synthèse avec les verbatims sources et les liens vers les études d’origine, sans passer des heures à relire des rapports.
Ce cas d’usage adresse un problème documenté par le Nielsen Norman Group : les research repositories souffrent d’un déficit de découvrabilité. Les insights existent mais personne ne les trouve, et le chercheur passe un temps considérable à compiler avant même de pouvoir interpréter.
Dovetail a intégré une fonctionnalité d’interrogation IA (« Magic Search ») qui utilise ce principe, avec des résultats jugés prometteurs mais encore imparfaits : taux de rappel incomplet, highlights manquants.
Accélérer l’analyse thématique
L’analyse thématique est le cœur de la recherche UX, mais aussi sa tâche la plus chronophage. Selon User Interviews (2025), 80 % des chercheurs UX utilisent déjà l’IA dans au moins une partie de leurs projets, un bond de 24 points par rapport à 2024.
Un workflow RAG appliqué à l’analyse thématique : indexer les transcriptions d’une étude, puis poser des questions comme « Quels sont les freins mentionnés par les participants pour l’adoption de la fonctionnalité X ? » Le système retrouve les passages pertinents et propose une synthèse thématique.
Ce workflow ne remplace pas le codage qualitatif. Il accélère la phase exploratoire : le chercheur obtient un premier panorama en minutes plutôt qu’en jours, qu’il affine ensuite manuellement.
Synthétiser le feedback multi-sources
Le feedback utilisateur arrive par de multiples canaux : support, NPS, avis app stores, interviews, tests d’utilisabilité. Rarement dans le même format, souvent dans des outils différents.
Un système RAG peut indexer ces sources hétérogènes et permettre des requêtes transversales : « Quelles sont les plaintes récurrentes sur la performance de l’app mobile, toutes sources confondues ? »
Des plateformes comme Dovetail, Looppanel ou Kapiche intègrent progressivement ce type de fonctionnalité, connectant des intégrations (Gong, Intercom, Zendesk, Slack) à une couche d’analyse IA.
Réduire les biais du chercheur
L’analyse manuelle est sujette aux biais cognitifs classiques : biais de confirmation, attention sélective, biais d’interprétation. Le RAG n’élimine pas les biais, il en a d’autres, mais il offre un filet de sécurité.
En parcourant systématiquement l’ensemble des données, il peut faire remonter des patterns que le chercheur n’aurait pas vus. La chercheuse Susanne Friese (2025) propose une méthode appelée CAAI (Conversational Analysis with AI) qui repositionne le chercheur comme facilitateur d’un dialogue analytique avec l’IA, plutôt que comme codeur solitaire.
L’écosystème des outils : qui fait quoi aujourd’hui
Les plateformes de research repository avec IA intégrée
Dovetail propose Magic Search, Magic Summarize et Magic Highlight : interrogation IA du repository, résumés automatiques, détection de moments clés dans les vidéos. Les retours terrain sont nuancés : la transcription est bonne, la recherche IA prometteuse mais le taux de rappel reste inégal.
Looppanel se concentre sur l’analyse d’interviews avec notes automatiques organisées par question, tagging assisté par IA et recherche sémantique. Apprécié pour la traçabilité : chaque insight est relié à sa source.
Condens adopte une approche plus légère, centrée sur la flexibilité du workflow d’analyse et la facilité d’adoption.
Les outils d’analyse qualitative augmentée
ATLAS.ti, outil académique de référence, intègre désormais un codage automatique basé sur GPT. Le chercheur définit ses intentions, l’IA code les données en conséquence.
NVivo et MAXQDA intègrent progressivement des fonctionnalités IA pour le codage, la visualisation et la détection de patterns dans les données textuelles, audio et vidéo.
Ces outils s’adressent davantage aux équipes recherche structurées qu’aux équipes produit qui cherchent de la rapidité.
Les plateformes d’interviews IA
Une nouvelle catégorie émerge : les outils qui combinent conduite d’interviews par IA et analyse automatique. Outset (utilisé par Microsoft pour Copilot) propose un modérateur IA qui mène des entretiens en texte, voix ou vidéo, avec relance dynamique, puis synthétise automatiquement les thèmes, verbatims clés et highlight reels.
Cette catégorie pose des questions méthodologiques spécifiques : qualité de la relance IA, profondeur des insights obtenus, et perte potentielle de la dimension empathique de l’entretien humain.
Le DIY : RAG custom avec des LLMs et outils ouverts
Pour les équipes techniques, monter un pipeline RAG custom est possible avec LangChain ou LlamaIndex pour l’orchestration, une base vectorielle (Pinecone, Chroma, Weaviate) et un LLM au choix. C’est un usage réel mais marginal : il nécessite des compétences techniques et une maintenance continue qui dépassent le périmètre de la plupart des équipes UX Research.
Pour les équipes qui cherchent une solution clé en main, Dust s’est imposé comme la référence du marché. La plateforme permet de connecter ses sources de données internes et de déployer des agents RAG configurables sans infrastructure à gérer.
Les limites et les risques : ce que le RAG ne fait pas (encore)
Le risque d’hallucination reste présent
Le RAG réduit significativement les hallucinations par rapport à un LLM seul, mais ne les élimine pas. Le modèle peut mal interpréter le contexte d’un passage retrouvé, ou amalgamer des données de sources différentes.
En UX Research, une hallucination est particulièrement dangereuse car elle se présente comme un insight fondé sur les données. Elle a l’apparence de la rigueur sans en avoir la substance.
Garde-fou essentiel : paramétrer le système avec un prompt de configuration solide et tester les réponses avant de faire confiance au système. Toute synthèse générée doit rester traçable, chaque affirmation reliée au verbatim ou au document source.
Le faux sentiment de complétude
Un système RAG ne retrouve que ce qu’il a indexé. Si vos données sont incomplètes, mal structurées ou mal découpées, la réponse sera partielle, mais présentée avec la même assurance qu’une réponse complète.
Le risque : un chercheur interroge le repository, obtient une réponse et se croit informé, alors que des données pertinentes n’ont simplement pas été indexées ou retrouvées.
Les retours terrain sur Dovetail illustrent ce problème : des highlights importants manquent dans les résultats de recherche IA, avec un taux de rappel estimé à 40-50 % dans certains cas d’usage.
La perte de contexte et de nuance
Le RAG travaille sur des segments de texte découpés. Cette segmentation peut séparer un propos de son contexte : le ton, l’hésitation, la contradiction, le non-dit.
En recherche qualitative, le sens se construit souvent dans la relation entre les propos, pas dans les propos isolés. Un verbatim extrait de son contexte peut dire le contraire de ce que le participant voulait exprimer.
L’IA excelle dans la détection de patterns de surface mais peine à saisir les drivers profonds. Looppanel le formule clairement : l’IA détecte les onboarding issues mais ne les relie pas aux enjeux de confiance ou de stratégie produit.
Les biais propres à l’IA
Le RAG ne supprime pas les biais, il a ses propres biais. Biais de récence (les documents récents sont sur-représentés), biais de volume (les thèmes fréquents écrasent les signaux faibles), biais de formulation (la façon de poser la question influence fortement les résultats).
L’apparence d’objectivité technologique peut rendre les utilisateurs moins critiques face aux biais de l’output.
La règle d’or : l’IA est un outil d’accélération, pas un outil de décision. Le jugement du chercheur reste indispensable pour interpréter, contextualiser et valider.
Bonnes pratiques : intégrer le RAG dans un workflow de recherche rigoureux
Le RAG est-il utile en toutes circonstances ?
Commencer par la qualité des données, pas par l’outil
Un système RAG est aussi bon que les données qu’il indexe. Des transcriptions de mauvaise qualité, des notes fragmentaires ou des rapports sans structure produiront des réponses médiocres.
Avant d’investir dans un outil IA, investir dans un repository structuré : conventions de nommage, taxonomie de tags cohérente, métadonnées (date, étude, segment utilisateur, méthode).
Le NNg recommande la même fondation pour les research repositories classiques. L’IA ne fait qu’amplifier l’importance de cette hygiène documentaire.
Valider son RAG avec un Golden Data Set
Une fois le système constitué, ne pas le prendre au mot. La bonne pratique consiste à établir un Golden Data Set : une série de questions de test dont vous connaissez déjà les réponses correctes, issues de vos données réelles.
Ce jeu de questions permet de mesurer la qualité des réponses du RAG, de détecter les zones de faiblesse (taux de rappel insuffisant, réponses trop vagues, hallucinations) et d’ajuster en conséquence : modifier la structure de la base de connaissance, affiner le découpage des segments ou retravailler le prompt de configuration.
C’est une étape non négociable avant de déployer le système à d’autres membres de l’équipe.
Exiger la traçabilité
Ne jamais accepter une synthèse IA sans accès aux sources. Chaque insight généré doit pointer vers le verbatim, la transcription ou le document d’origine.
C’est le critère numéro 1 de choix d’un outil : la traçabilité complète, de la réponse au segment source jusqu’au participant d’origine. Cette exigence protège contre les hallucinations et maintient la rigueur méthodologique attendue en recherche.
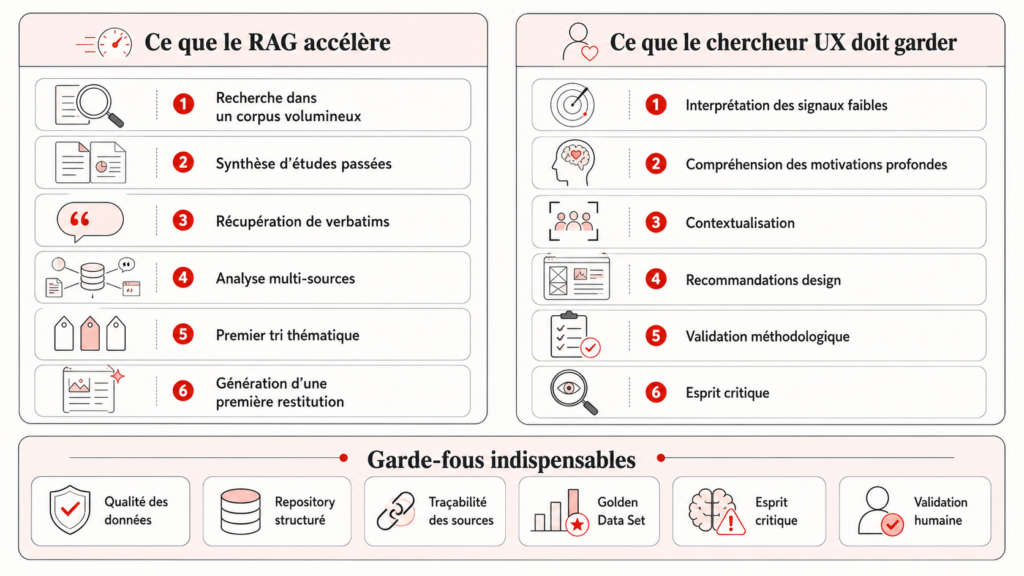
Positionner l’IA sur les bonnes tâches
L’IA est pertinente pour la transcription, la recherche dans un corpus large, le premier tri thématique, la synthèse multi-études et la génération de rapports structurés.
L’IA n’est pas pertinente pour l’interprétation de signaux faibles, la compréhension des motivations profondes, la formulation de recommandations design ou la validation d’hypothèses de recherche.
La méthode CAAI (Friese, 2025) propose un cadre en cinq étapes : se familiariser via les résumés IA, structurer des questions d’analyse, dialoguer avec l’IA sur 4 à 6 interviews à la fois, synthétiser les dialogues, puis élever l’analyse en testant des hypothèses théoriques.
Conserver un regard critique
L’IA ne remplace pas le chercheur, elle l’augmente. La valeur ajoutée du chercheur UX est dans le cadrage des questions, l’interprétation contextuelle, la mise en perspective stratégique et la relation empathique avec les participants.
Le risque organisationnel est réel : si l’IA facilite l’accès aux données, elle peut aussi créer l’illusion que la recherche se résume à poser des questions à un chatbot, ce qui dévalue le métier et la rigueur méthodologique.
Le rôle du chercheur évolue : moins de temps sur le codage manuel et la compilation, plus de temps sur le design de recherche, l’interprétation et l’impact stratégique des insights.
Le RAG ne remplace pas la recherche, il la rend enfin exploitable
Le vrai problème de la recherche utilisateur n’a jamais été le manque de données mais le manque d’exploitation. Des insights précieux dorment dans des rapports que personne ne consulte, des patterns se répètent d’une étude à l’autre sans que personne ne les connecte.
Le RAG apporte une réponse structurelle à ce problème en rendant les données de recherche interrogeables, synthétisables et accessibles à l’équipe recherche, qui peut enfin se concentrer sur ce qui compte : produire des insights, alimenter le desk research et influencer les décisions produit.
Mais cet accès élargi exige un cadre. Traçabilité, esprit critique, Golden Data Set pour valider la qualité des réponses : sans ces garde-fous, le RAG ne fait qu’automatiser le chaos.
La question pour chaque équipe : avez-vous les données, la structure et la posture critique pour tirer parti du RAG, ou risquez-vous simplement d’automatiser le chaos ?
